适用场景
已有明确目标表位,希望围绕该位置获得全新候选抗体序列
传统免疫或筛选难以稳定命中目标表位,需要更定向的设计入口
我们使用Cookie来改善您的浏览体验并分析网站流量。继续使用本站即表示您同意我们的Cookie政策。 隐私政策
无需动物免疫,直接针对特定表位从头生成全新抗体。核心依赖三大 AI 模型:AbGenerator 生成多样化 CDRH3 序列,AffinityEvaluator 预测结合概率,AbEvolver 模拟亲和力成熟。
验证数据
为什么需要?
"抗体结合的表位不同,药效甚至安全性都会不同。然而当前主流方法倾向于命中免疫优势区域,对低免疫原性或隐蔽表位,候选抗体往往稀缺甚至为零。"
Key Advantages
传统方法倾向命中免疫优势区域,针对隐蔽、保守等困难表位,往往难以获得有效抗体。不同表位可能带来不同药效、安全性和作用机制。
当前主流抗体发现方法无法保证获得目标表位抗体。对低免疫原性表位、稀有功能表位及复杂膜蛋白靶点,候选抗体常常稀缺甚至无法命中。
CDRH3 区构象高度灵活,抗体缺乏丰富共进化信息,抗体结构和抗原/抗体复合物数据规模显著更小,设计难度远超普通蛋白 binder。
最大优势在于能够精准控制抗体的抗原表位结合,避免传统免疫方法的随机性,实现"指哪打哪"的理性设计。
基于生成模型从头设计 CDRH3,突破传统模板库与已有 binder 优化路径的限制,拓展候选序列空间。
生成的抗体具有全人源特性,减少免疫原性;所有设计抗体共享相同轻链,避免重链/轻链错配。
结合模型预测与结构特征对候选序列评分筛选,输出候选序列、排序与设计报告,支持团队评审与实验决策。
Validation
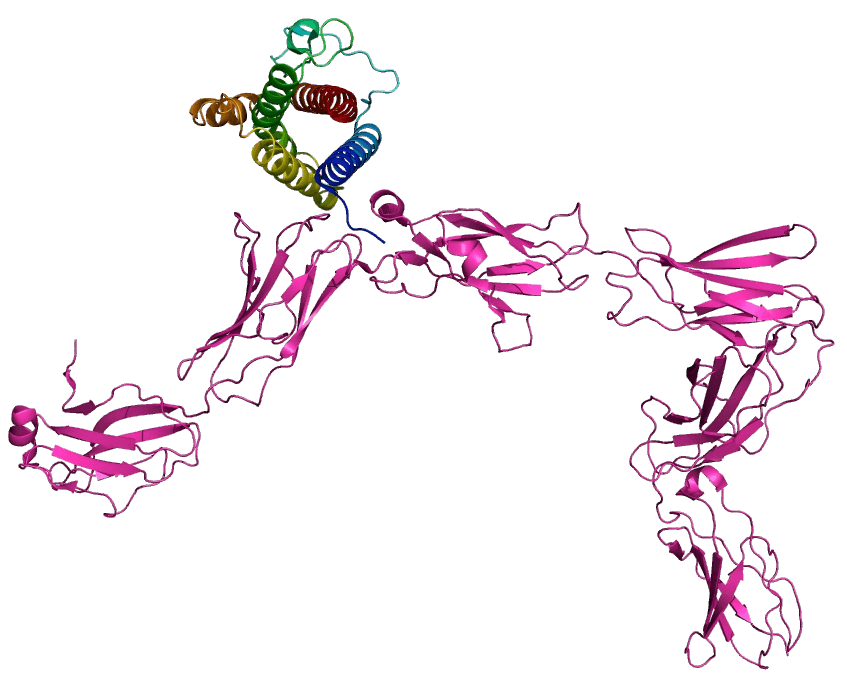
在多个抗原靶点上,已完成特定表位抗体从头设计验证。针对指定表位设计 1 万级候选抗体后,经湿实验验证可获得多条能够结合目标表位的抗体,亲和力覆盖微摩尔到纳摩尔范围。
KD 达 10-7 至 10-9 M;其中 2 条可阻断天然配体结合,并在细胞层面观察到 STAT-3 磷酸化抑制活性,冷冻电镜进一步验证了 P211858 的准确表位。

| Antibody | KD (M) | ka (1/Ms) | kd (1/s) |
|---|---|---|---|
| P95531 | 7.10E-07 | 2.01E+04 | 1.43E-02 |
| P211853 | 1.03E-07 | 1.39E+04 | 1.43E-03 |
| P211854 | 7.60E-09 | 8.50E+04 | 6.46E-04 |
| P211855 | 9.62E-08 | 9.14E+03 | 8.79E-04 |
| P211856 | 7.04E-08 | 9.20E+03 | 6.48E-04 |
| P211857 | 9.35E-08 | 9.46E+03 | 8.84E-04 |
| P211858 | 5.87E-09 | 9.68E+04 | 5.68E-04 |
| P211859 | 3.97E-09 | 1.70E+05 | 6.75E-04 |
| Sample | Value |
|---|---|
| P211858 | 159.5 nM |
| P211859 | 68.30 nM |
| Positive Control | 12.53 nM |
| Sample | Value |
|---|---|
| P95531 (PC) | 0.04748 |
| P211854 | 0.02238 |
| P211855 | 1.319 |
| P211856 | 0.6156 |
| P211857 | 2.490 |
| P211858 | 0.06618 |
| P211859 | 0.03155 |
| Sample | Value |
|---|---|
| P95531 (PC) | 9.840 |
| P211853 | ~ 0.2025 |
| P211854 | ~ 0.000 |
| P211855 | ~ 1.004e+029 |
| P211856 | ~ 0.000 |
| A083 (P211857) | ~ 0.1119 |
| P211858 | 0.2076 |
| P211859 | 0.1756 |
Pipeline
用户指定抗原表位后,围绕这个表位进行抗体设计、结构预测和筛选,最终交付符合预期的全新抗体。
实验验证包括:ELISA / BLI / 表位竞争 / 冷冻电镜 / 细胞实验验证
Report
以下为抗体从头设计服务交付报告的部分截图,展示了从表位分析到候选序列评估的完整流程。
Lab Guide
设计抗体基于百奥赛图全人源共轻链 RenLite 小鼠训练数据,计算报告提供重链 HCDR3、重链 FR1-FR3 和共轻链序列。以下指南帮助您从计算结果顺利过渡到实验验证。
将报告中的三部分序列拼接成 scFv:① 重链 FR1-FR3(计算推荐 10-20 种匹配框架) + ② 重链 HCDR3(可选 1万/20万/100万 三种量级,oligopool 合成) + ③ 重链 FR4-Linker-VK(共轻链部分,固定序列)。
线性化 scFv 片段需进行质控,确保正确构建比例 ≥60%。正常情况下少量错误构建对展示筛选影响较小。
采用 噪菌体展示筛选(亦可采用酵母展示),3 轮以上筛选后,通过 phage ELISA 判断富集,经单克隆筛选或 NGS 测序获得阳性 binder 序列。
将阳性 binder 可变区构建为全长 IgG(如 huIgG1/kappa),使用 CHO/HEK293 真核表达系统。
结合活性检测
可溶性抗原:ELISA / BLI / SPR;多次跨膜抗原:过表达细胞系或肿瘤细胞 FACS 检测。
表位验证
竞争 ELISA / Epitope Binning 快速分析;更进一步可通过 Cryo-EM / X-ray 结构生物学方法确认。
💡 提示:噪菌体筛选时建议设置阳性菌库(将已知结合抗体或 Benchmark 抗体以 1:10000 比例混入筛选库)作为内控。如需提升亲和力,可直接返回平台使用亲和力成熟流程。
适用场景
适合已经明确功能表位、希望围绕该表位获得可建库候选的项目。
传统方法很难保证命中指定表位,尤其是低免疫原性或稀有功能表位。从头设计的优势是把起点放在“目标表位”上,通过生成式 AI 直接设计 CDRH3 和框架组合,减少随机筛选带来的不确定性。
CDRH3 是抗体识别抗原的关键区域,但构象灵活、已知结构数据少,传统模板或已有 binder 优化路径容易受限。平台用生成模型扩展 CDRH3 序列空间,让指定表位项目有更多可筛选候选。
全人源特性有助于降低免疫原性风险;共享轻链可以减少重链/轻链错配,降低候选表达和后续 CMC 复杂度,让计算结果更容易进入实验验证。
报告会结合模型预测、结构特征和候选序列排序,帮助团队优先选择更可能命中目标表位、且更适合建库和筛选的序列,而不是只拿到一批未排序候选。